A week ago, I attended Ian Watt‘s workshop on Wikidata at the Scottish Open Data Unconference 2020. It was an interesting session and it got me thinking about how we might upload some our datasets of interest (e.g. amounts of waste generated & recycled per Scottish council area, ‘carbon impact’ figures) into Wikidata. Would having such datasets in Wikidata, be useful?
There is interest in “per council area” and “per citizen“ waste data so I thought that I’d start by uploading into Wikidata, a dataset that describes the populations per Scottish council area per year (source: the Population Estimates data cube at statistics.gov.scot).
This executable notebook steps through the nitty-gritty of doing that. SPARQL is used to pull data from both Wikidata and statistics.gov.scot; the data is compared and the QuickStatements tool is used to help automate the creation and modification of Wikidata records. 2232 edits were executed against Wikidata through QuickStatements (taking about 30 mins). Unfortunately QuickStatements does not yet support a means to set the rank of a statement so I had to individually edit the 32 council area pages to mark, in each, its 2019 population value as the Preferred rank population value …indicating that it is the most up-to-date population value.
But, is having this dataset in Wikidata useful?
The uploaded dataset can be pulled (de-referenced) into Wikipedia articles quite easily. As an example, I edited the Wikipedia article Council areas of Scotland to insert into its main table, the new column “Number of people (latest estimate)” whose values are pulled (each time the page is rendered) directly from the data that I uploaded into Wikidata: 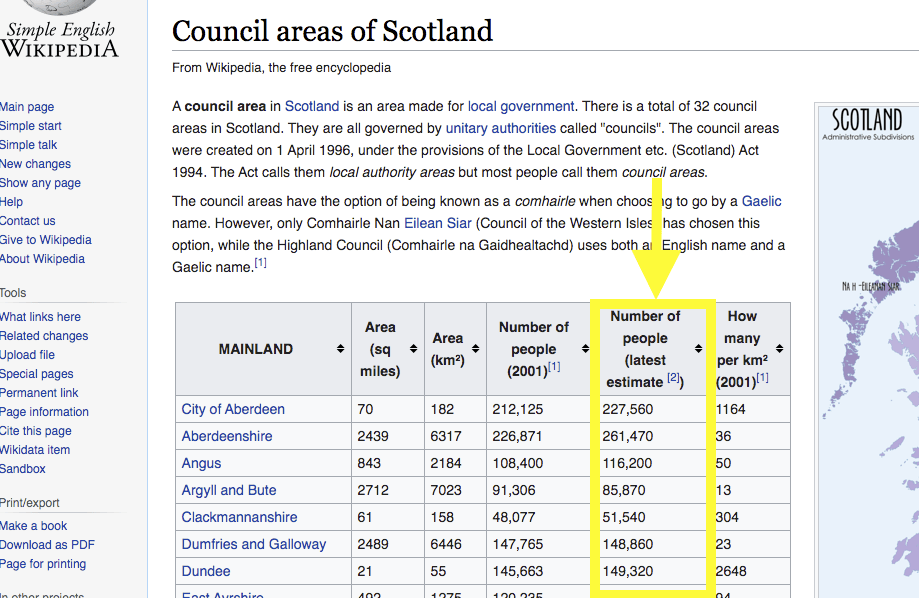
Visualisations based on the upload dataset can be embedded into web pages quite easily. Here’s an example that fetches our dataset from Wikidata and renders it as a line graph, when this web page is loaded into your web browser:
Concerns, next steps, alternative approaches.
Interestingly, there is some discussion about the pros & cons of inserting Wikidata values into Wikipedia articles. The main argument against is the immaturity of Wikidata’s structure: therefore a concern about the durability of the references into its data structure. The counter point is that early use & evolution might be the best path to maturity.
The case study for our Data Commons Scotland project, is open data about waste in Scotland. So a next step for the project might be to upload into Wikidata, datasets that describe the amounts of household waste generated & recycled, and ‘carbon impact’ figures. These could also be linked to council areas – as we have done for the population dataset – to support per council area/per citizen statistics and visualisations. Appropriate properties do not yet exist in Wikidata for the description of such data about waste, so new ones would need to be ratified by the Wikidata community.
Should such datasets actually be uploaded into Wikidata?…These are small datasets and they seem to fit well enough into Wikidata’s knowledge graph. Uploading them into Wikidata may make them easier to access, de-silo the data and help enrich Wikidata’s knowledge graph. But then, of course, there is the keeping it up-to-date issue to solve. Alternatively, those datasets could be pulled dynamically and directly from statistics.gov.scot into Wikipedia articles with the help of some new MediaWiki extensions.
Some follow-on work in this executable notebook, explores adding a CO2e dataset into Wikidata, and then making use of both the uploaded population and CO2e datasets to generate a chart showing, for household waste, the tonnes of CO2e generated per citizen per year per Scottish council area.