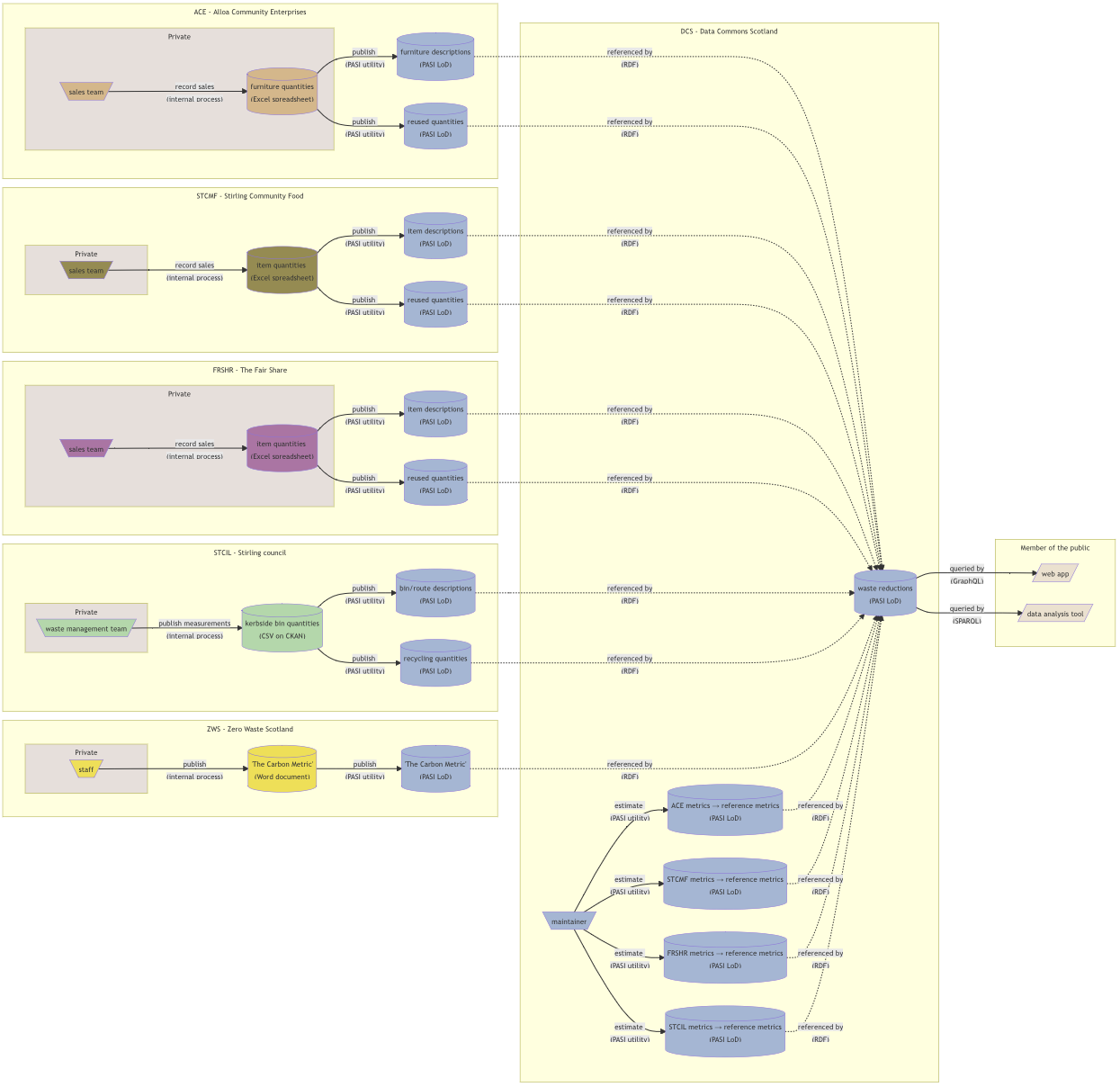
The Open Data Scotland website provides an up-to-date list of the Open Data resources about Scotland. It is being developed by the volunteer-run OD_BODS project team, and the idea for it originated from Ian Watt’s Scottish Open Data audit.
The website has been built using the JKAN framework which provides to end users, a ready-made search-the-datasets feature (try the search box near to the top of this page). However, its search can sometimes excessively exclude because it returns only those datasets whose metadata contain all of the search words, consecutively.
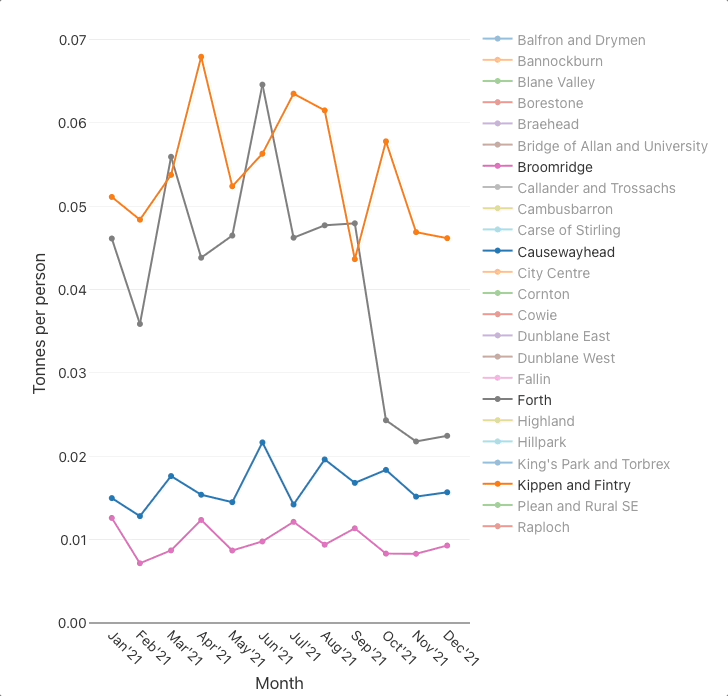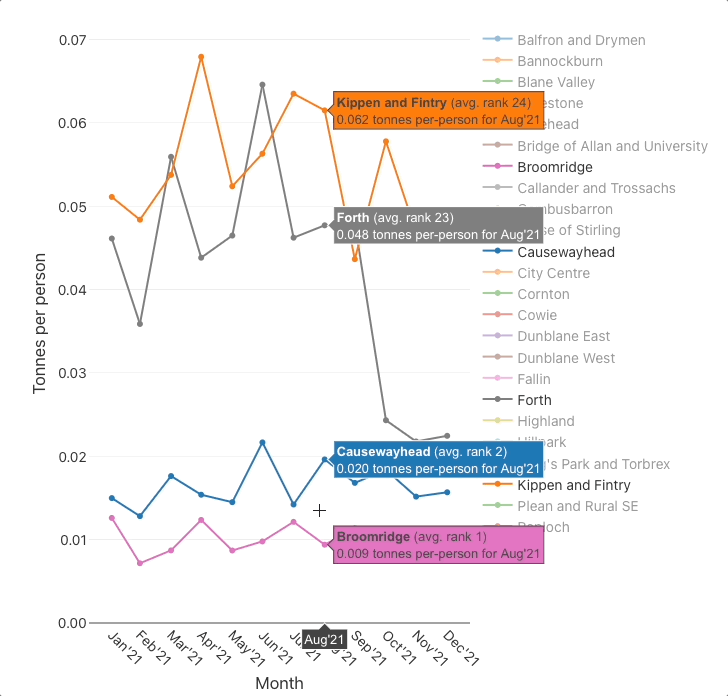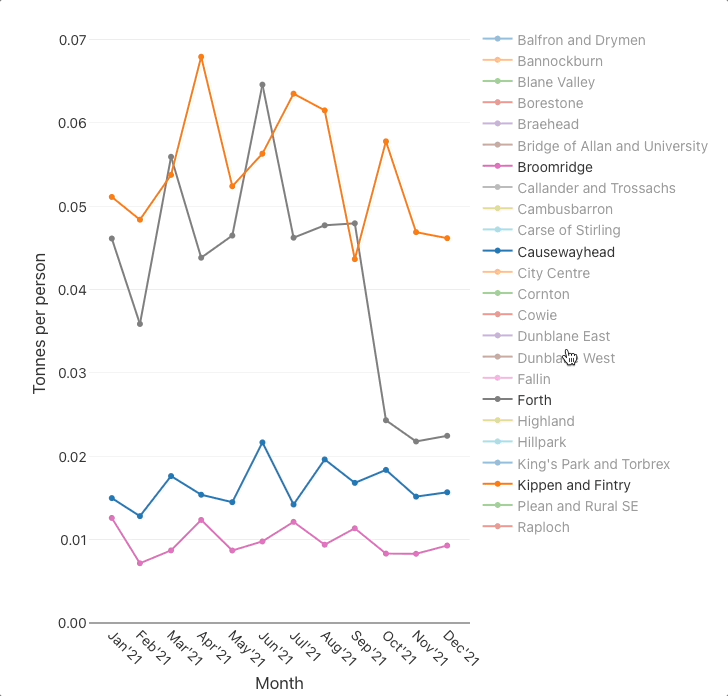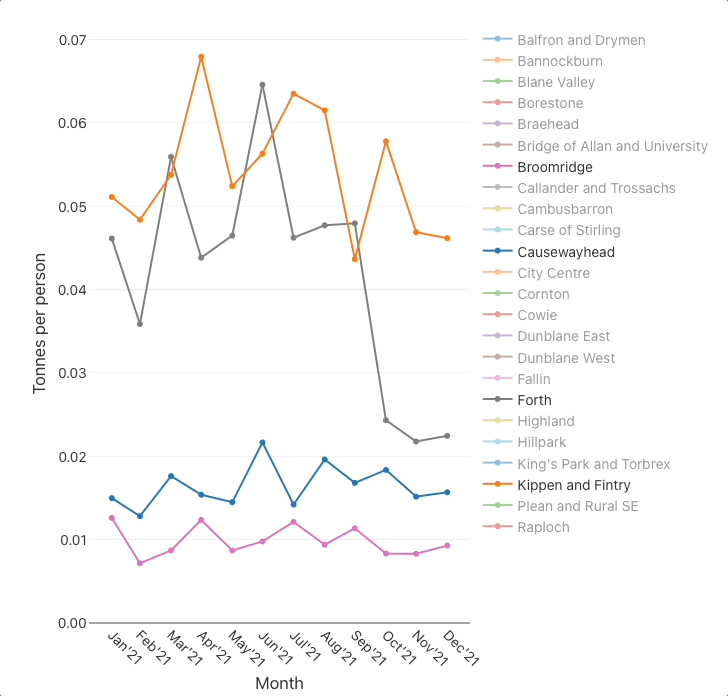
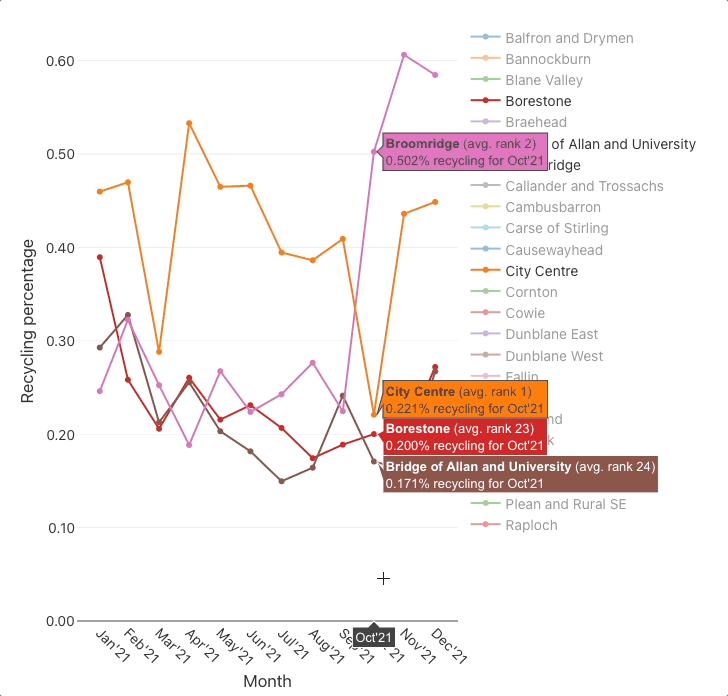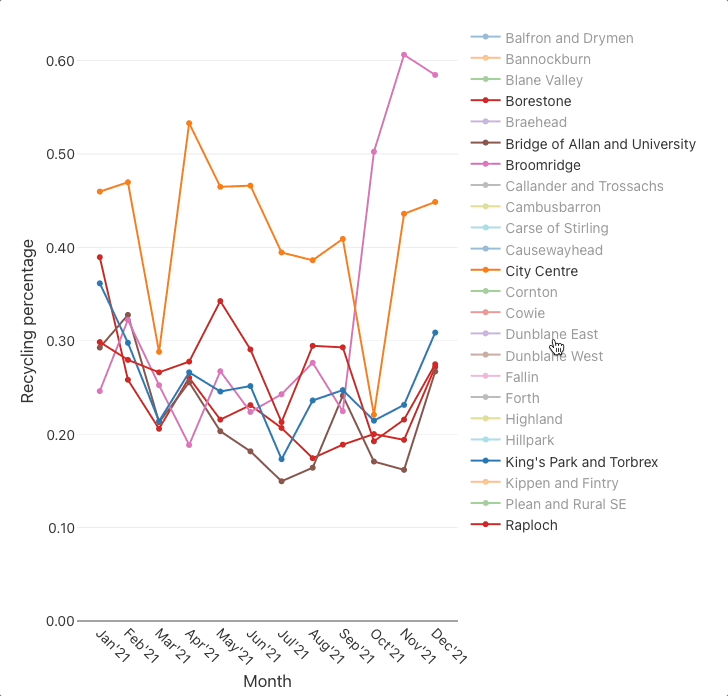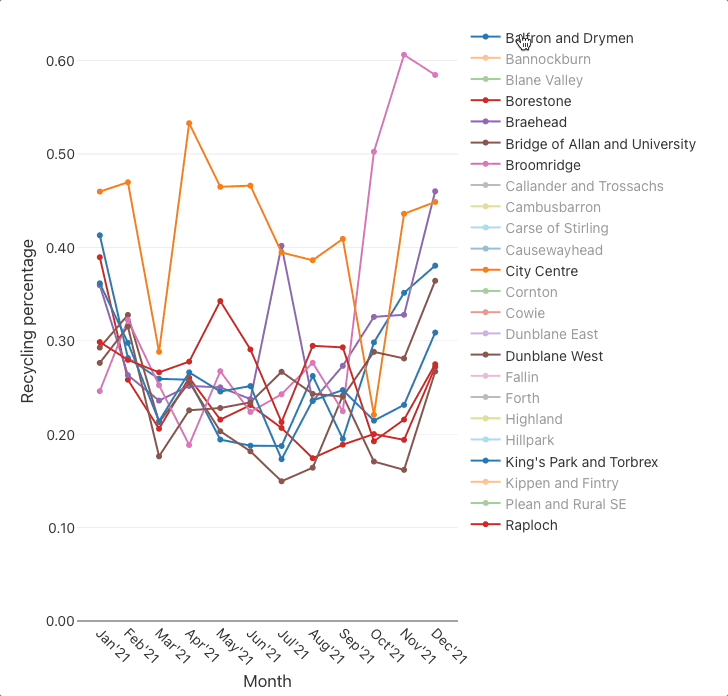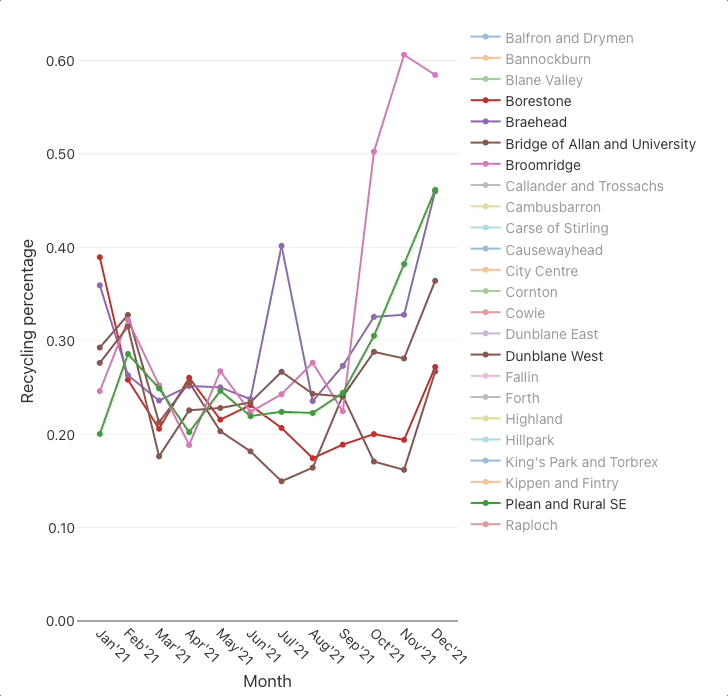
For instance, say that we wanted to find all datasets related to waste management. We might think of entering the search words: waste management recycl bin landfill dump tip. With JKAN, we would fairly much have to search for each of those words individually then collate the results.
Search tuning is its own whole field of research/area of business but, we have built a simple alternative to the JKAN search, to better support exploratory searching. Click on the image below to try the demo.