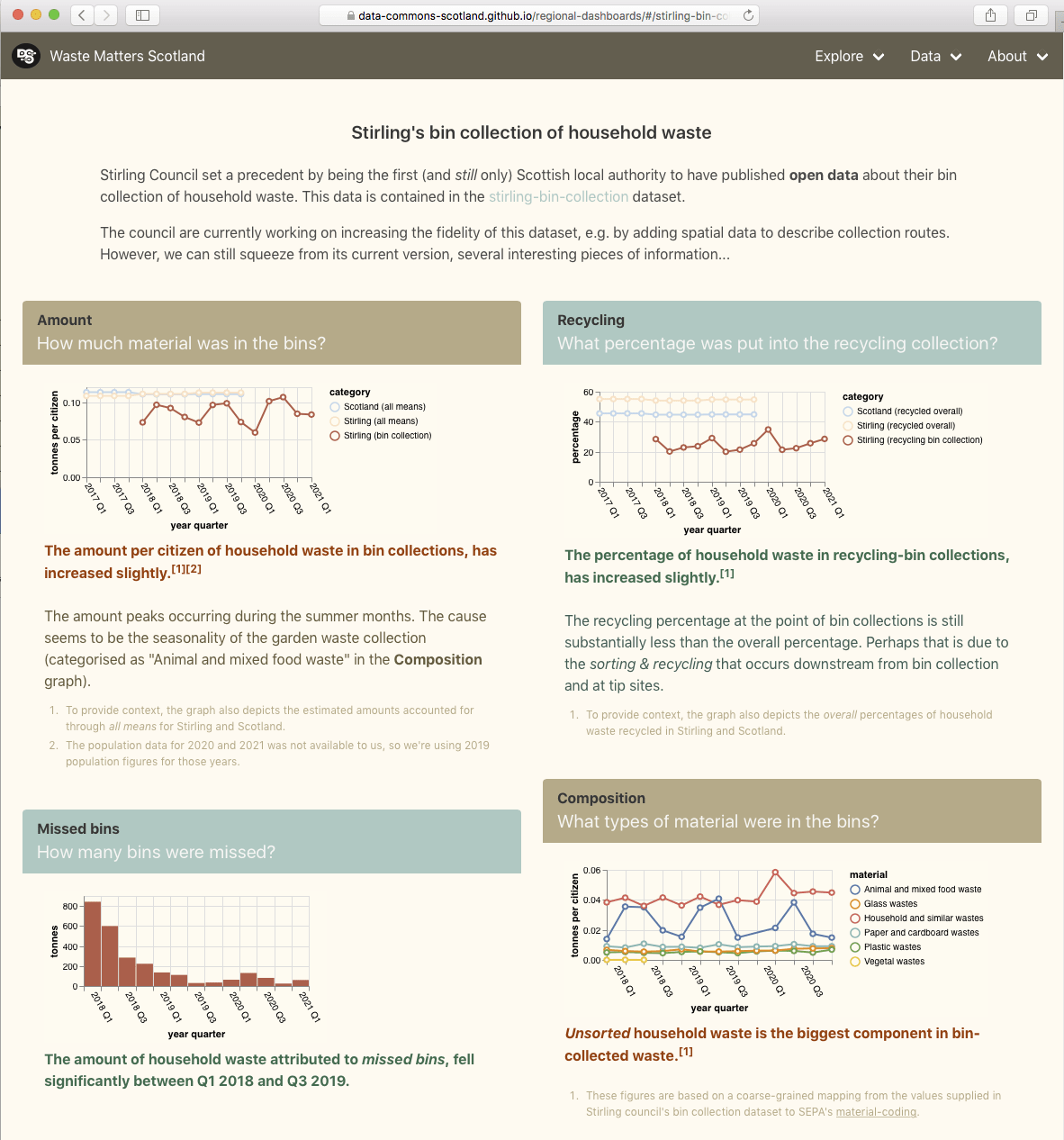
With Glasgow City hosting the UN Climate Change conference (COP26) later this year, it was appropriate that this year’s The Data Lab data analysis hackathon (held last week) had the theme “pollution reduction”.
Three organisations provided challenge projects for the hackathon teams: we provided a “waste management” project based on our easier-to-use datasets; Code the City provided an “air quality” project; and Scottish Power an “electric vehicle charging” project.
The hackathon was lead by a young Scottish tech start-up company called Filament. They have an interesting product that is basically a sharable, cloud-hosted Jupyter Notebook.
Each day a new cohort of teams would tackle the project challenges. We helped by answering their questions about our datasets, and by suggesting ideas for investigation.
At the end of each day the teams presented their findings.
It was informative to see how the teams (each with a mix of skills that included programming, data analysis and business acumen) organised themselves for group working, handled the data, and applied learned analysis techniques.
The teams had a relatively short amount of time to work on their projects so having easy to use datasets was a deciding factor in how much they could achieve. Therefore one take-away is clear, and helps substantiate an aim of our DCS project… open data needs to be easy to use, not just be accessible. Making data easier to use for non-experts, opens it to a much wider audience and to much more creativity.