Preface
Shortly before the end of 2020, I attended the Code The City 21: Put Your City on the Map hack weekend which explored ideas for putting open data onto geographic maps.
It ran several interesting projects. There was one was especially inspiring to me: the Bioregion Dashboard. Its idea is to tell an evidence-backed story-through-the-years, involving interactive data displays against a map. James Littlejohn introduces it in this YouTube video.
This got me thinking about new ways to depict the information that is bound up in the data about waste…
In particular, thinking about a means to convey at-a-glance, to the lay person, how councils areas compare through time in respect of the amounts of (household solid) waste that they process. Now, the grid & graph prototype that we built a couple of months back, conveys that same information very well (and with a greater fidelity than we will mange in this work) but, to the lay parson like me, it isn’t attention grabbing. I like seeing something with movement and with features that I can relate to, such as animated charts and a geographical map.
The prototype webapp
Leveraging what I learnt at the Code the City 21 hack weekend, I hacked together a prototype webapp that shows how waste quantities change through time, on a geographic map.
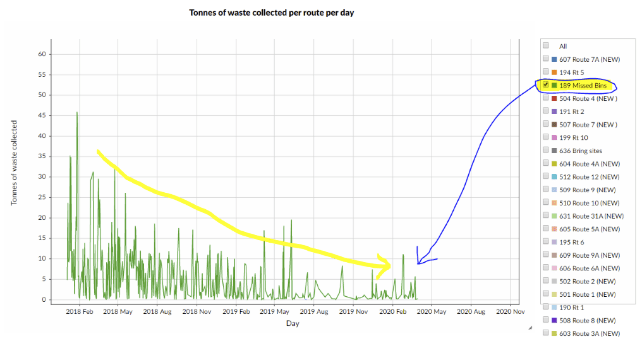
The below, animated image of the webapp, it conveys that landfilled-waste is reducing over time whilst total-waste is remaining fairly constant.

UI controls
- The dataset of interest is chosen through the
 control, either:
control, either:
- Tonnes of managed solid household waste per person per year.
- Tonnes of C02 equivalent from household waste per person per year.
- Use the
 control to travel through time.
control to travel through time. - Each
 chart depicts the waste-related quantities for a council area.
chart depicts the waste-related quantities for a council area.
- The sizes of its slices and its overall size, are related to the quantities that it depicts.
- Hover over a council area to see detailed metrics in the
 panel.
panel. - The usual map zoom and pan controls are supported.




Software and datasets
- The open source Leaflet and Minichart libraries take care of most of the heavy lifting (interactive graphics).
- The map’s base layer comes from Esri ArcGIS (although the images in this document contain a Stadia Maps base layer – but this can’t be used in a runtime without a licence.)
- The map’s council area boundary data originates from the ONS, and has been curated by Martin Chorely.
- The datasets for the pie charts, are:
- “Population Estimates (Current Geographic Boundaries)” curated in the Scottish government’s linked-data store, and authored by NRS in 2020.
- “Generation and Management of Household Waste” curated in the Scottish government’s linked-data store, and authored by SEPA in 2020.
- “Carbon footprint” authored by SEPA in 2020.

‘Live’ instance
A ‘live’ instance of this webapp can be accessed here .
Closing thoughts
I haven’t seen these datasets about waste shown in this way before, and I think that it usefully conveys aspects of the datasets in a catchy and easy to understand way. It is low fidelity when compared to a full data grid with graph solution, but the idea is to hold the attention of the average person in the street.
Future work could integrate additional waste-relevant datasets that have geography and time dimensions. Also we should consider alternative metrics (such as ratios), alternative charts (such as bar or polar) and alternative statistics (such as deviation or trend). I went with the ‘most straightforward’ but user-testing might indicate that an alternative is better.