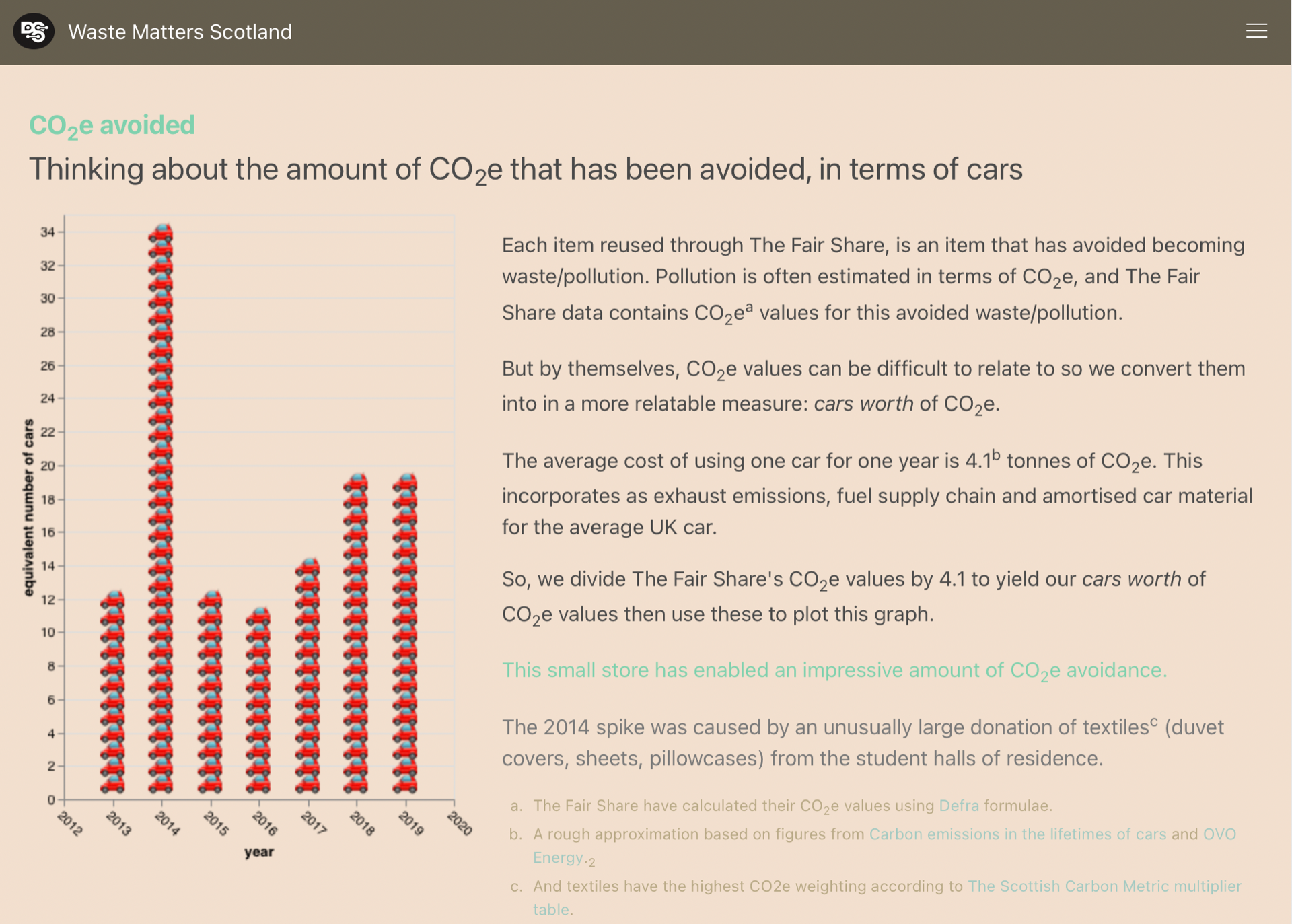
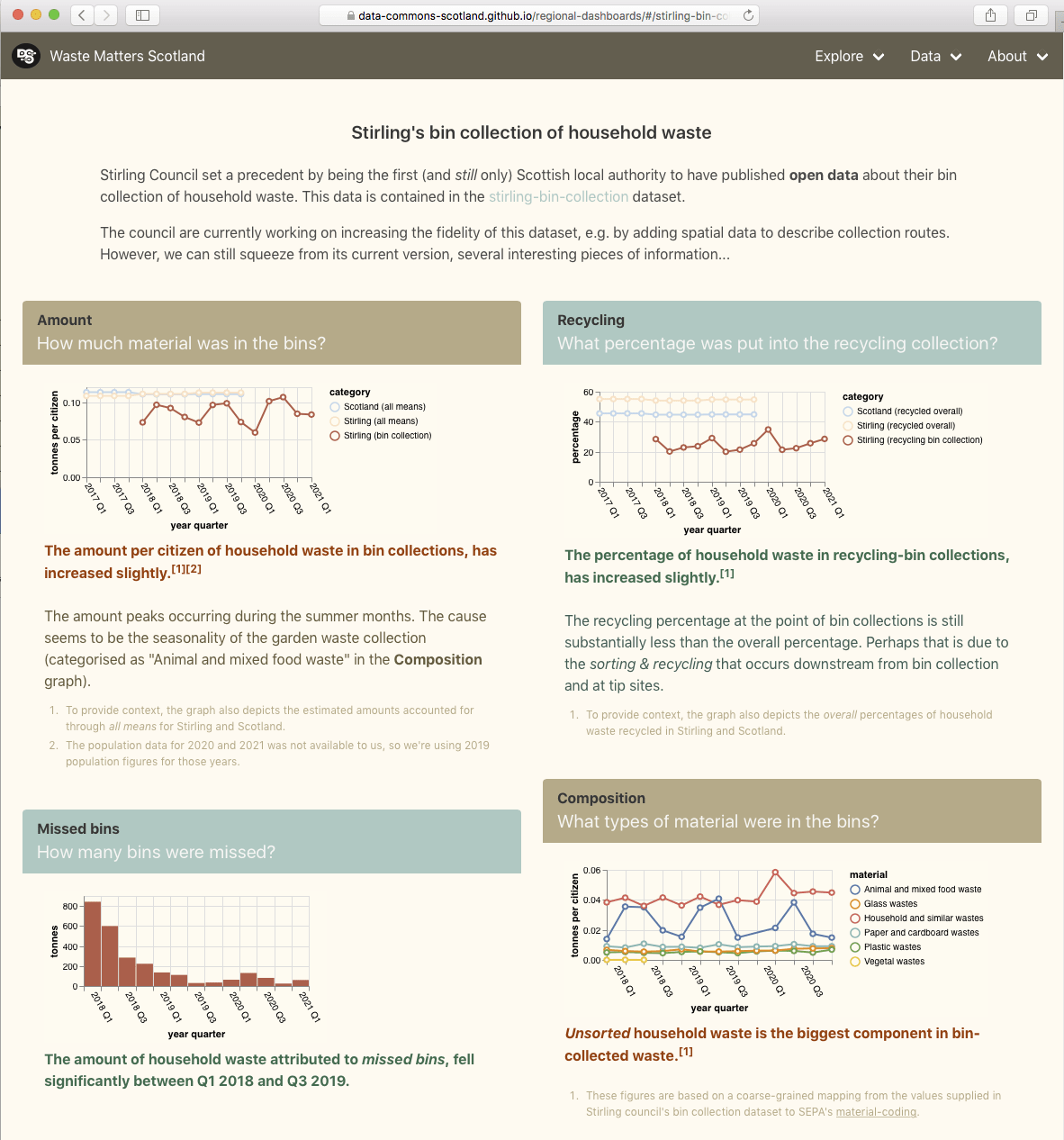
Over the weekend (2-3 Sept 2021), I represented our DCS project at SODU 2021 – Scotland’s annual conference on Open Data.
Organised and run by the Code the City team, this event always provides a great opportunity to catch up with others in Scotland’s friendly Open Data community, and hear about their news.
This year, for me, its highlights included:
- A “corridor chat” that began ad-hoc, about the preservation of railway history as represented by its data records (mostly paper based).That lead us to discuss Git persistence, the zeitgeist for shared ledger databases with explicit temporal support, and what all of that might mean for recording Open Data!
- Then, a session on the perhaps more immediate concern of: how to nudge the government into making open, more of the data which it holds. Proposed was the neat idea of aggregating, curating and making searchable all of the responses arising from FOI-requests to local and national government. This would help highlight data that that the government should be making open by default.
- And it was heartening to see representatives from the Scottish government’s Open Data team attending the conference and running an engaging session that brought together government and community perspectives. The government’s recent initiative to “make public sector data easy to find” was one of the topics discussed.
- The conference even gained an international dimension when two attendees joined us from Sweden to help run a live editing session on Wikidata, contributing to the project to add better data about Scottish government agencies into Wikidata.
- Our own project received some valuable feedback after I demo-ed our latest prototype website.This wasn’t just all affirmative!… I got some useful insights into what what people found difficult. For example, “I like the site’s tools and visualisations but, more needs to be done to help me navigate my path-of-interest through the prototype website“. This nicely ties in with one of our project’s (as yet unrealised) goals: to weave interest-based navigation maps through our data site.
I enjoyed the friendly SODU sessions over the weekend – it was inspiring to hear what others are contributing towards making data more open and accessible.
This year’s SODU was online because of Covid-19. Hopefully next year it will return to its more physical manifestation in Aberdeen city!